Imageretrieval
Image retrieval using pLSA
Image Retrieval
Image retrieval using pLSA
The dataset used is first 1000 images of MIRFLICKR-25000 Link
It is an unsupervised learning algorithm by Probabilistic Latent Semantic Analysis. Check the paper for more.
Coarse color histogram quantized to 1000 levels is used as a feature. The 1000 levels used are here
pLSA can be also applied to text, example it can cluster a series of articles into various topics like sports, politics, movies etc.
In this application the first 1000 images are used to learn the topic model based on the coarse color histogram. Later, the learnt model is used to retrieve k most similar images. Similar image means, which are similar by topics. For this application 6 topics are chosen.
We can see from the learnt topic model below that each topic has some pattern.
1. Topic 1 has brown shades as dominant color.
2. Topic 2 has shades of light-ish green and some more assorted ones.
3. Topic 3 has shades of orange ? as dominant color. ( I think its orange)
4. Topic 4 has shades of blue as dominant color.
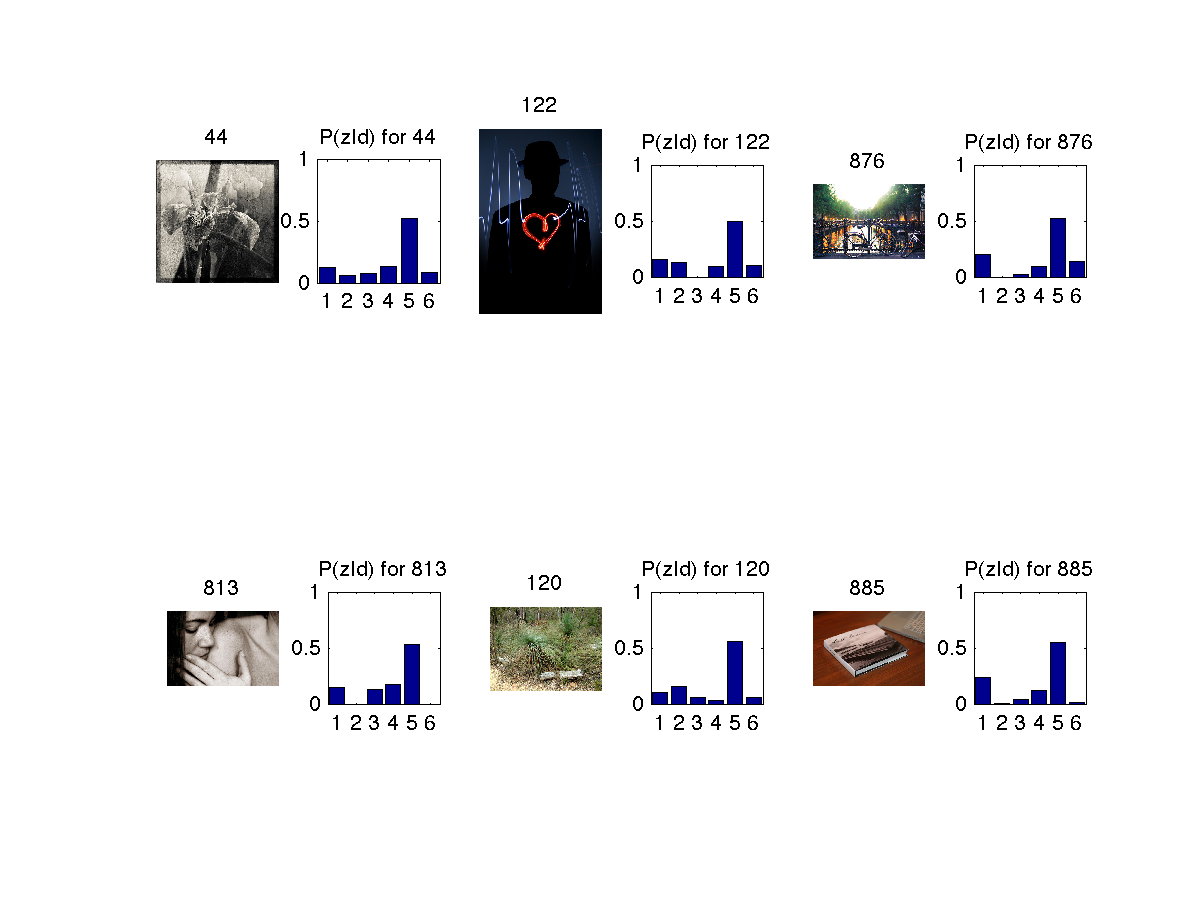
5. Topic 5 has shades of grey as dominant color and some dark colors. (No pun(s) intended ;)
6. Topic 6 has shades of green as dominant color.
Learnt 6 topic model is

Some images from each topic 1

Some images from each topic 2
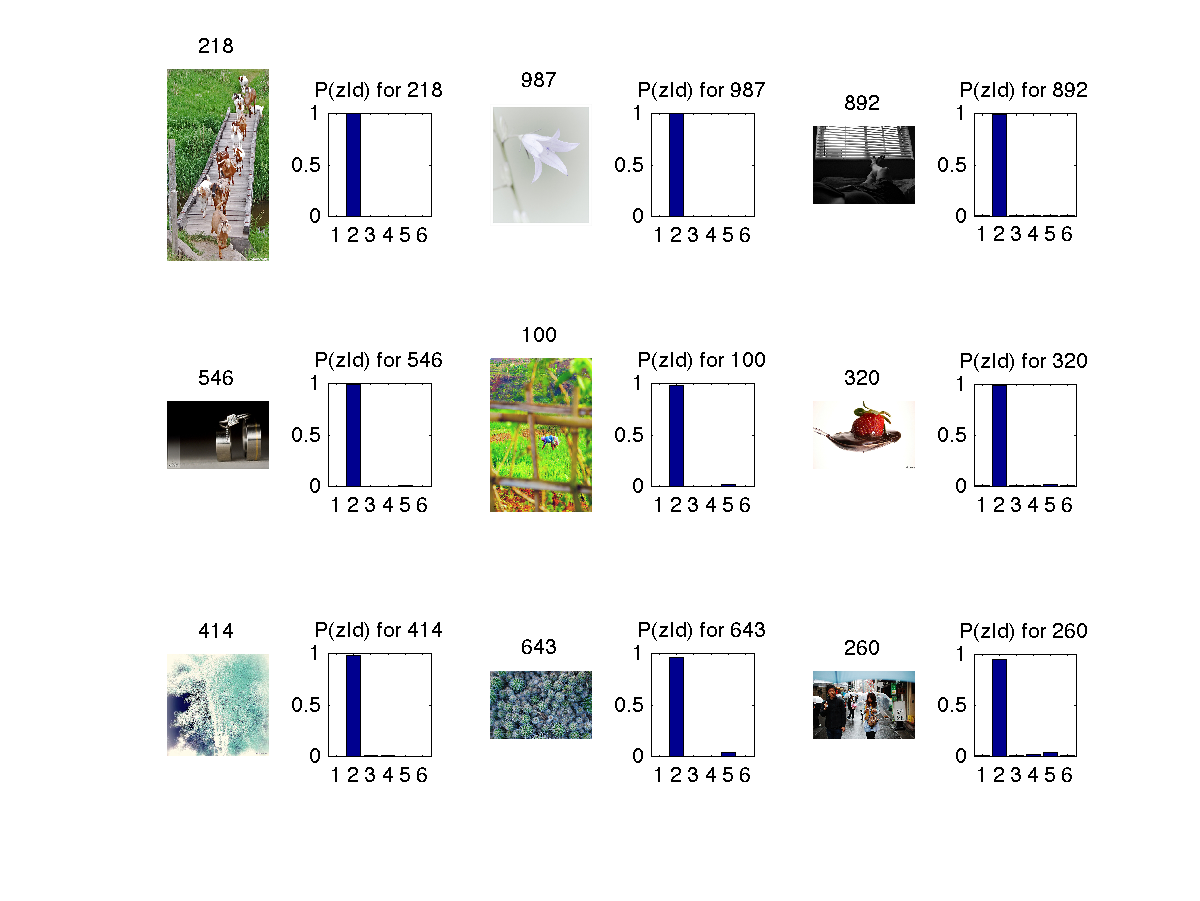
Some images from each topic 3
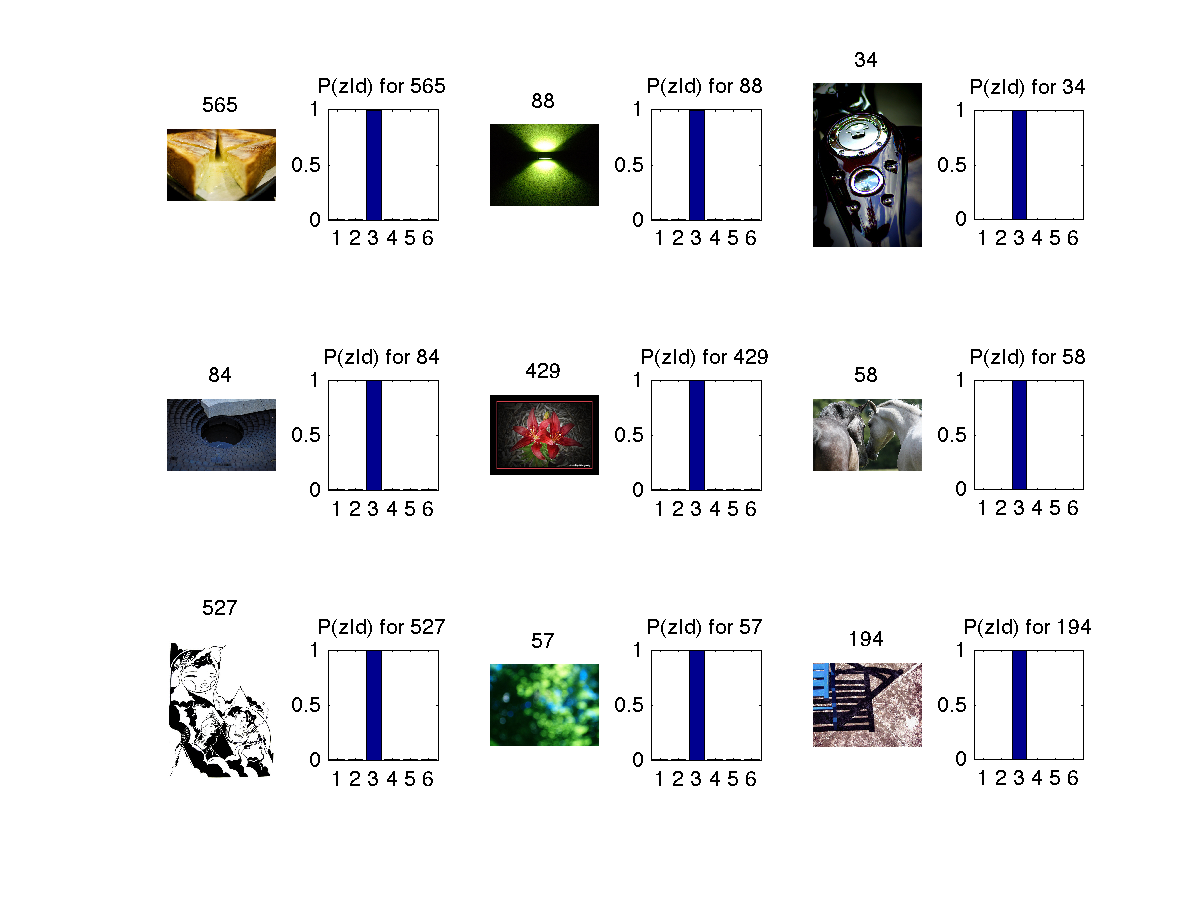
Some images from each topic 4
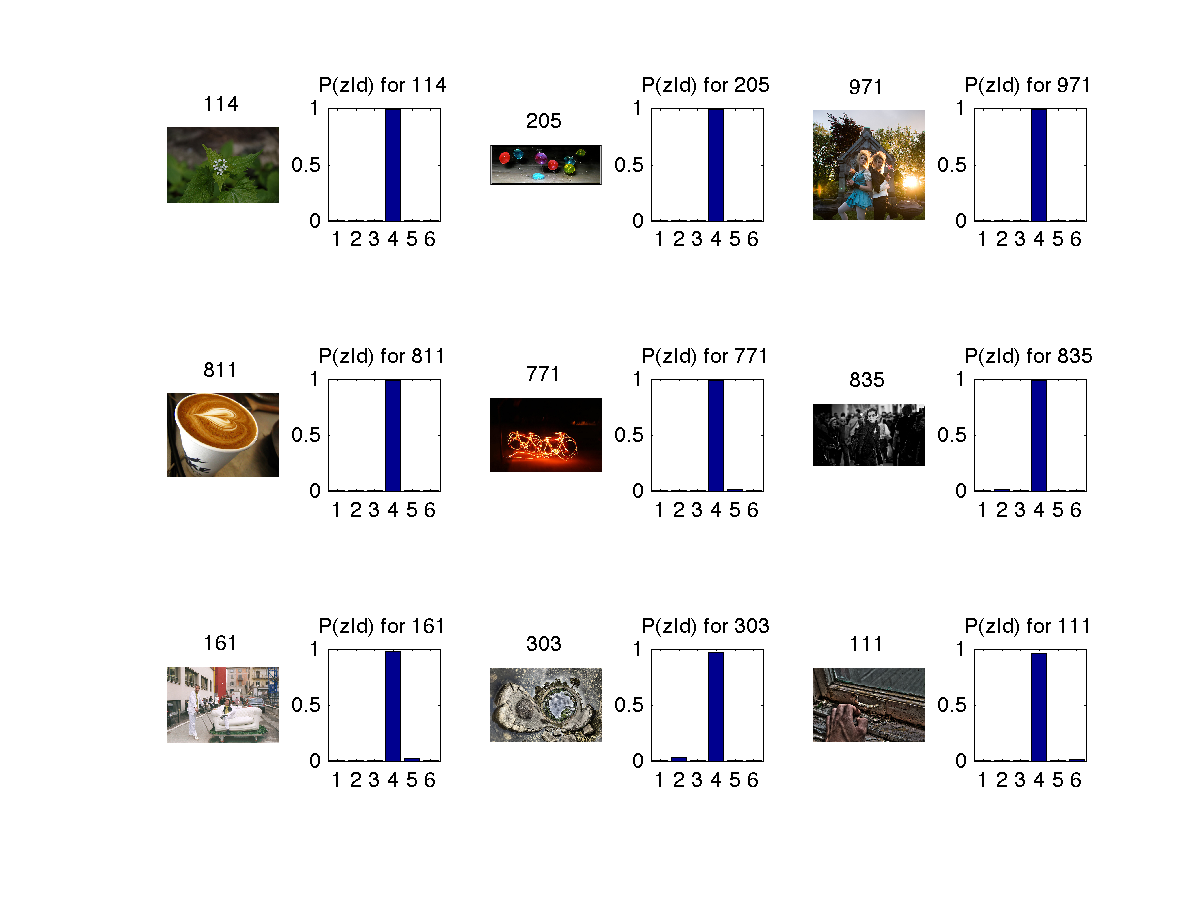
Some images from each topic 5
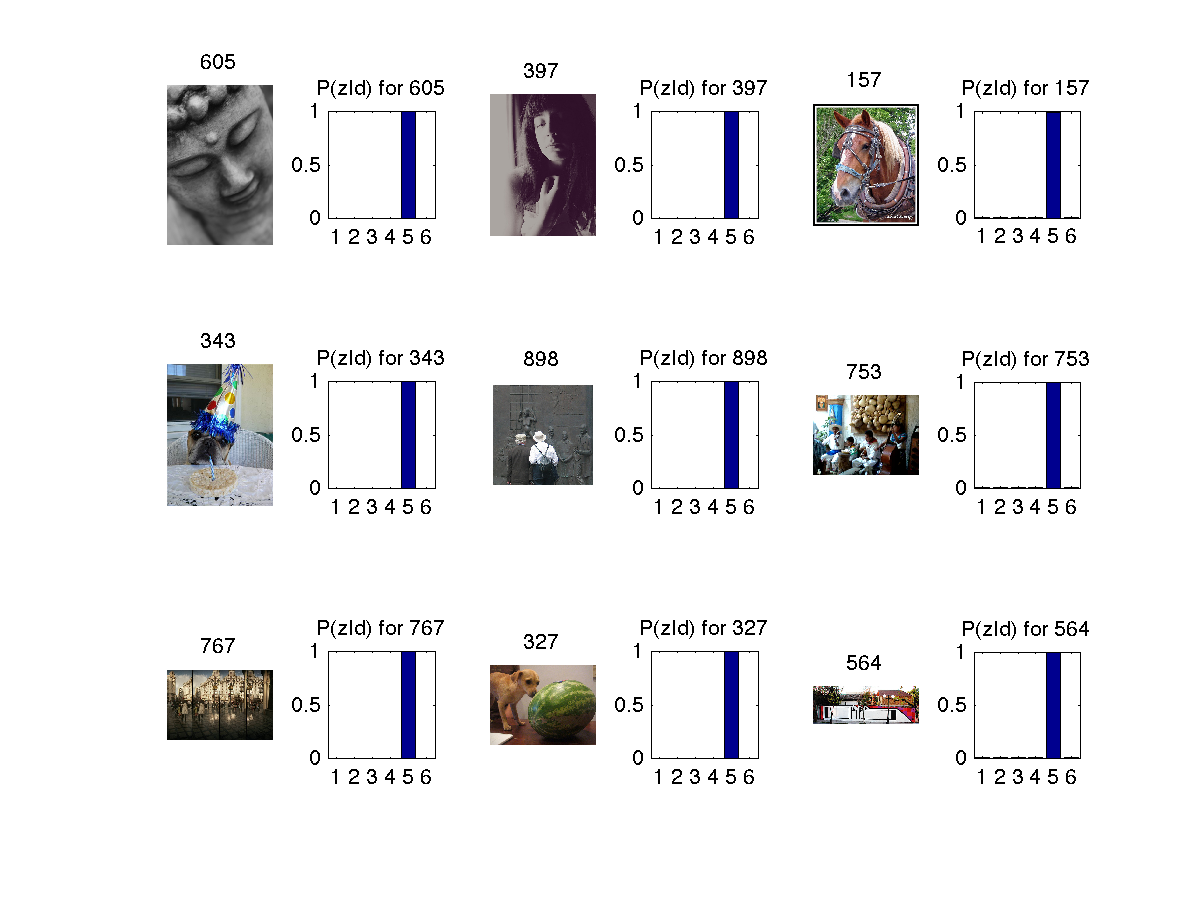
Some images from each topic 6
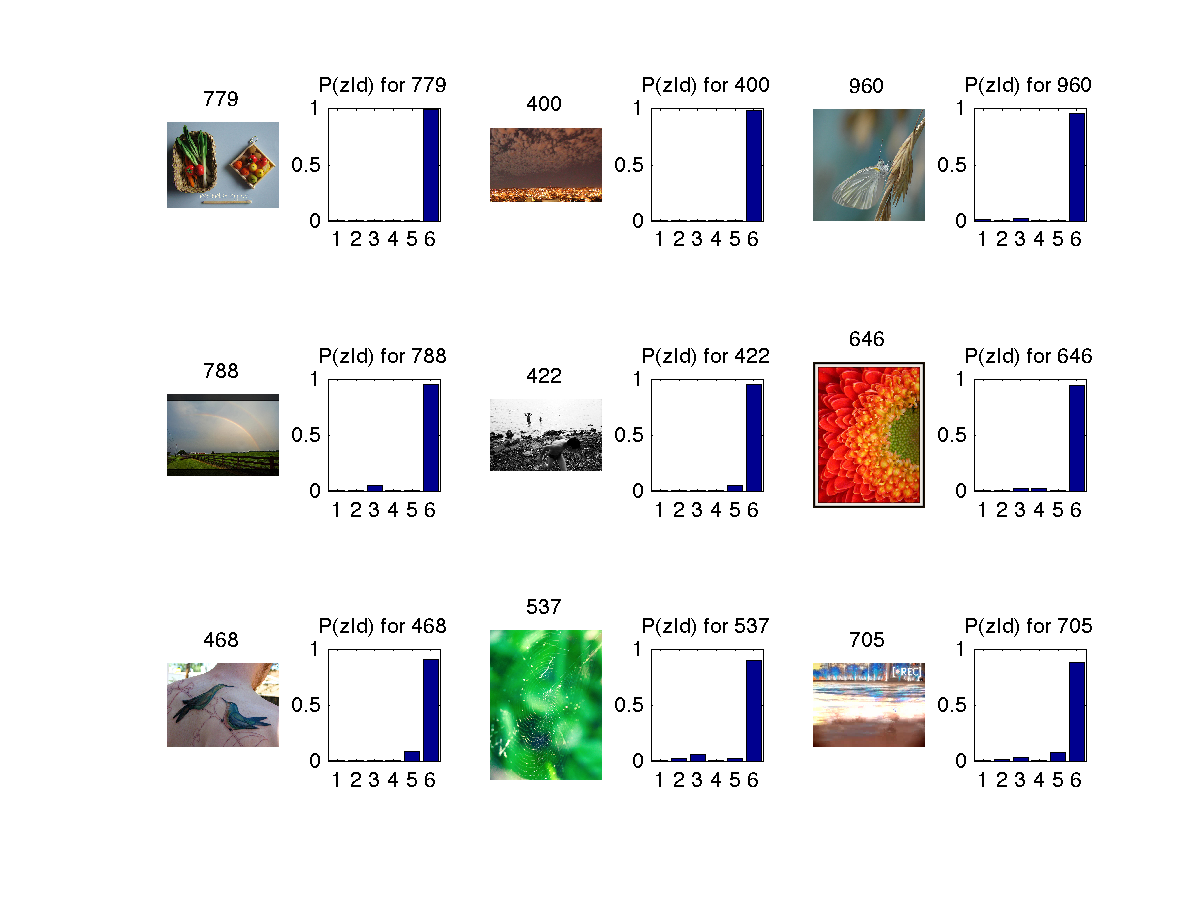
In the below images z refers to topics (1 to 6) and d refers to image (document) and w refers to feature(word).
Retrieval Example
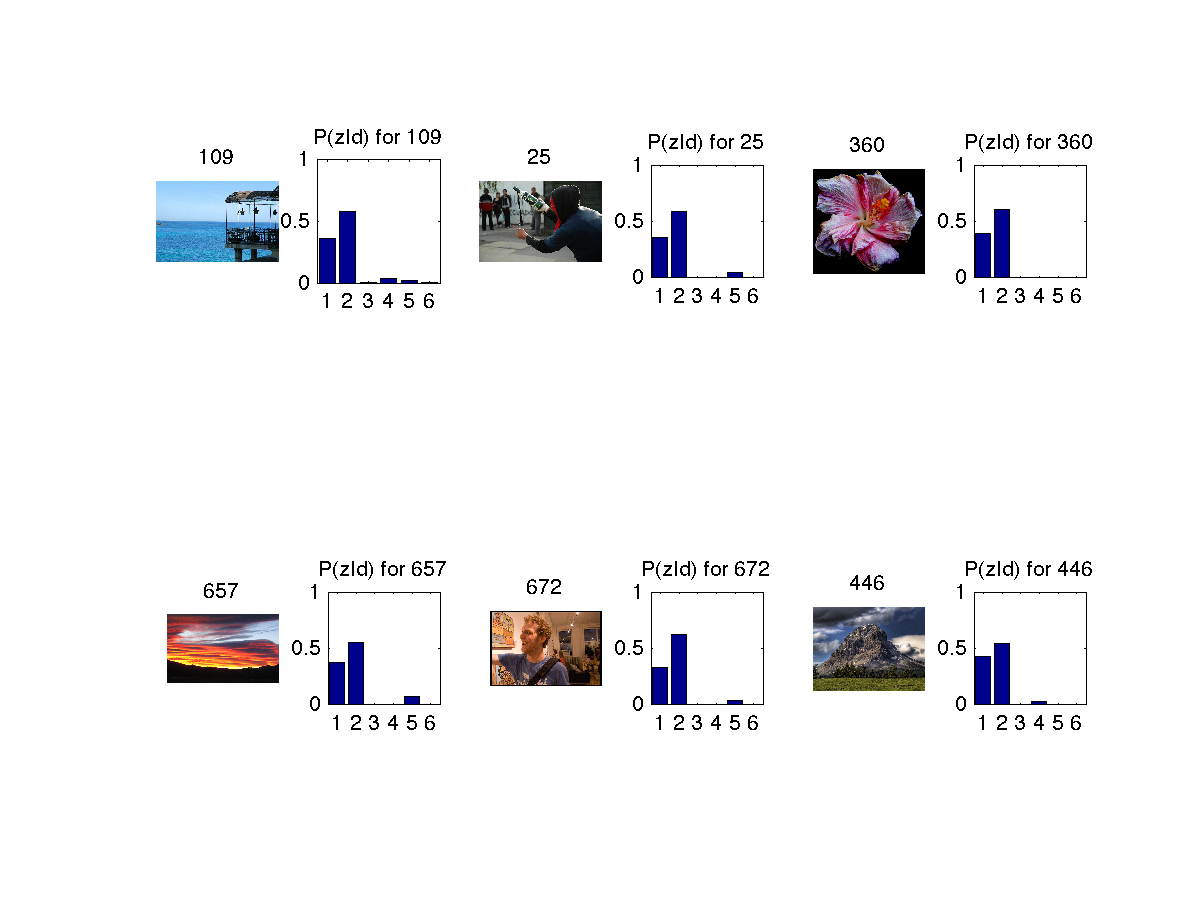
Similar images retrieved based on 1st image(titled 109) is
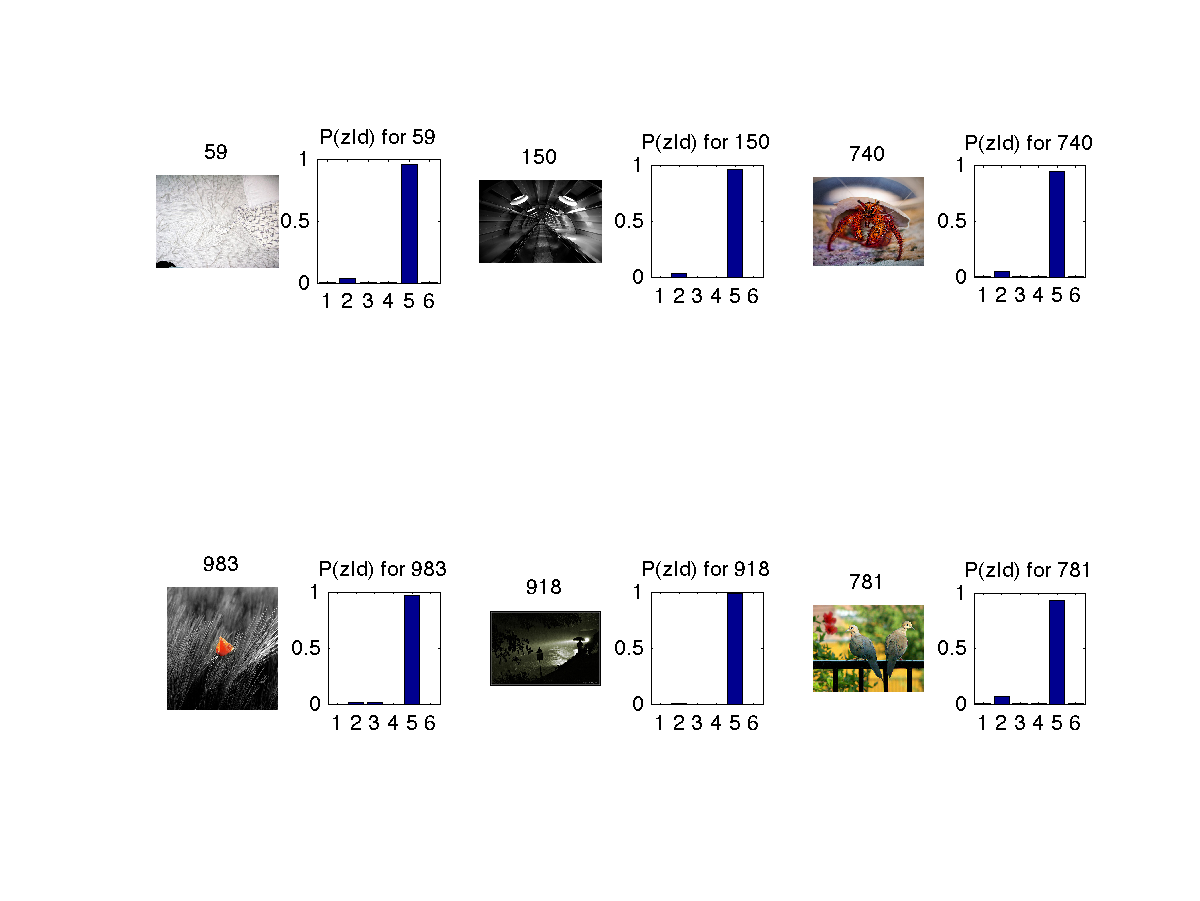
Similar images retrieved based on 1st image(titled 59) is
Similar images retrieved based on 1st image(titled 44) is